Understanding AI Models
From a training syllabus to local low-bit models, reasoning, tools, memory and multi-agent orchestration — a comprehensive, plain-English manual with examples, analogies, diagrams and cited sources.
From training syllabus to local low-bit models, reasoning, tools, memory and multi-agent orchestration — a comprehensive plain-English manual with examples, analogies, diagrams and cited sources.
What this manual covers. How large language models are created, trained, specialised, aligned, distilled and quantised; why models use FP16 and mixed precision; how PrismML’s binary and ternary approach differs from ordinary post-training quantisation; and how context windows, caches, tools, memory, skills and multi-agent orchestration turn a model into a practical local or cloud AI system.
1. The big picture
A modern language model is not made in one step. It is built through a chain of decisions: what material it studies, how its neural network is designed, how it is trained, how its behaviour is refined, whether knowledge is distilled into a smaller student, how its numerical weights are compressed, and how the finished model is connected to tools, memory and other agents.
A useful analogy is education. The training corpus is the syllabus and library. Pre-training is the long general education. Instruction tuning is vocational training in how to answer people. Safety alignment is professional conduct and supervision. Distillation is a smaller student learning from a more capable teacher. Quantisation is rewriting the student’s notes in a compact shorthand. Agent software is the workplace around the graduate: tools, files, calendars, memory and colleagues.
Each stage trades capability against cost, speed, memory use and reliability. For local AI, the practical question is not simply, “Which model has the most parameters?” It is, “Which model preserves the abilities I need, fits in my RAM or VRAM, and runs efficiently on my hardware?”
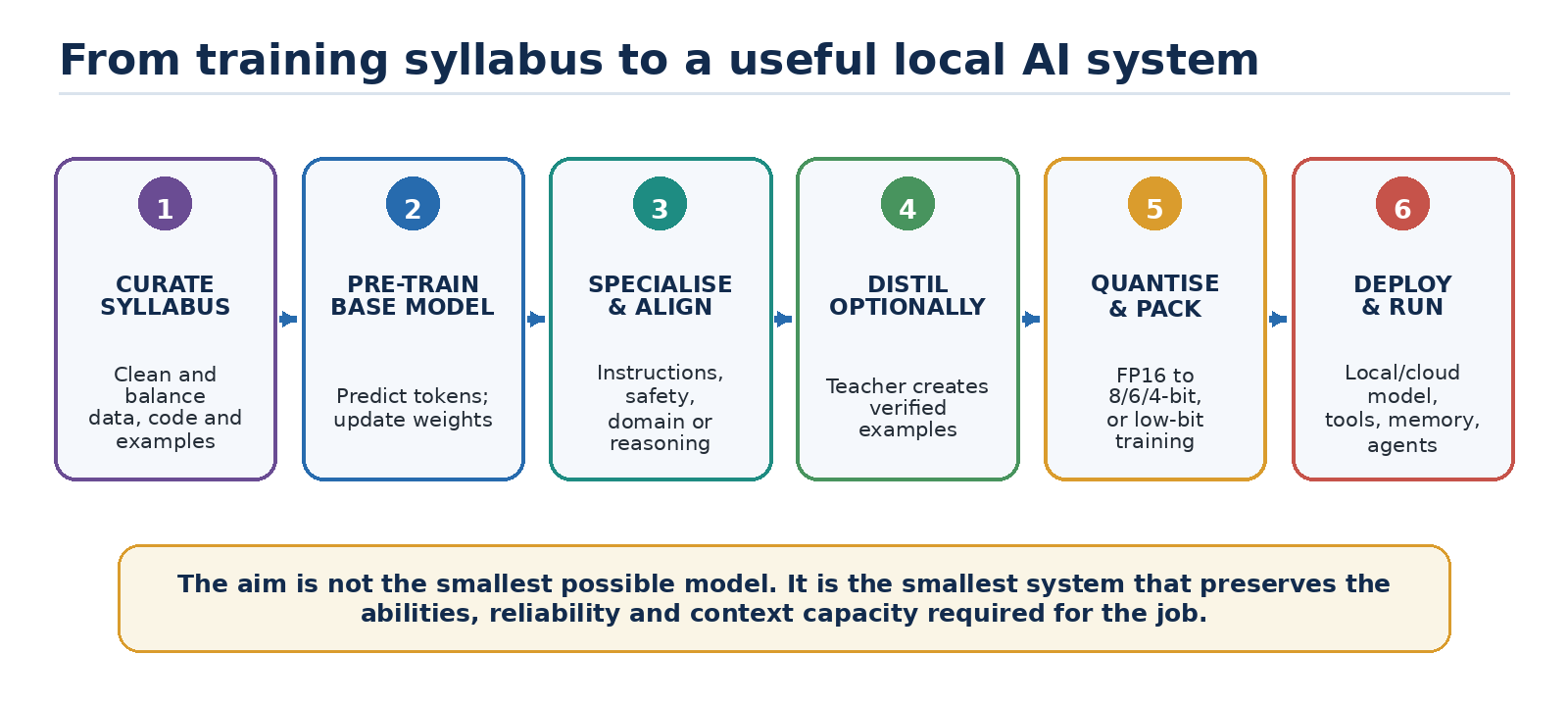
Figure 1. The full journey from curated training data to a practical local or cloud AI system.
Read the diagrams as maps, not as rigid recipes. Real systems may skip stages, repeat them, or combine several stages in one training programme.
2. Creating the learning syllabus
The syllabus is the collection of text, code, images or other material used to train the model. It may contain books, websites, scientific papers, software repositories, conversations, worked mathematics and specialist documents. Large training projects do not simply shovel everything into a model. They normally filter low-quality pages, remove duplicates, balance languages and subjects, and attempt to remove unsafe, private or legally problematic material. Meta’s Llama 3 report describes extensive data cleaning, deduplication and quality filtering before training. [1]
Why does this matter? A model learns statistical patterns from what it sees. If its syllabus contains excellent code but little medicine, it may become a strong coding model and a weak medical model. If one ideology or writing style dominates, its answers can inherit that imbalance. Repeated misinformation may be learned as though it were ordinary language.
Imagine training a chef. A vast pile of recipes is not automatically a good culinary education. Ten thousand copies of the same poor recipe add volume but not wisdom. A curated syllabus tries to provide broad coverage, trustworthy examples, difficult exercises and enough variety for the model to generalise beyond memorised passages.
The material is then broken into tokens. A token can be a whole short word, part of a longer word, punctuation or a piece of code. The sentence “unbelievable results” might become pieces resembling “un”, “believ”, “able”, and “results”. The model works with token numbers, not directly with letters on a page.
3. Tokens, embeddings and Transformer layers
Each token is first converted into an embedding: a long list of numbers representing how that token is being used. An embedding is not a dictionary definition. It is more like a location on a very large map of relationships. Words used in similar settings tend to occupy related regions of that map.
The embeddings pass through many Transformer layers. A layer is one repeated stage of processing, rather like one group of specialists reviewing the same document and passing an improved version to the next group. A typical large model may contain dozens of layers. Each layer refines the numerical representation of every token.
Within each layer, self-attention asks: “Which earlier tokens matter to the token I am processing now?” Consider: “The trophy would not fit in the suitcase because it was too large.” To interpret “it”, the model must pay attention to “trophy” and “suitcase” and infer which object is too large. Attention does not produce human understanding in a magical sense. It calculates relevance scores and combines information from useful positions in the text. The Transformer architecture made this style of parallel attention central to modern language models. [2]
After attention comes a feed-forward network, usually called an MLP, meaning multilayer perceptron. An MLP is a small neural network inside every Transformer layer. Attention gathers relevant information; the MLP transforms it. A simple analogy is a meeting followed by private thinking. Attention listens to the useful speakers around the table. The MLP takes those notes and changes the current internal representation: strengthening some patterns, suppressing others and constructing new combinations.
At the end, an output layer produces a probability for every possible next token. After “The capital of France is”, the model might assign a high probability to “Paris”, lower probabilities to other city names, and tiny probabilities to unrelated tokens. One token is selected, appended to the text, and the process repeats. A language model therefore generates a response one token at a time, even when the answer appears to arrive as a fluent paragraph.
4. Pre-training: error, loss, weights and backpropagation
Before training, the model’s weights are mostly random. A weight is a number that controls the strength and direction of one influence inside the network. Suppose an internal feature representing “plural subject” should increase the probability of a plural verb. A positive weight might strengthen that influence; a negative weight might suppress it. One weight alone does not store a complete fact. Useful behaviour is distributed across enormous patterns of weights.
During pre-training, the model is shown a sequence and asked to predict a hidden next token. Imagine the training sentence is “The cat sat on the mat.” The model sees “The cat sat on the” and predicts “roof” with 50 per cent probability, “mat” with 20 per cent, and other words with the remainder. The correct answer is “mat”, so the prediction is poor.
A loss function converts that wrongness into a single score. The score is not an emotional judgement. It is a mathematical measure used for comparison. Giving the correct token a low probability creates a relatively high loss; giving it a high probability creates a low loss. The training system wants the average loss across many examples to fall.
Backpropagation then works backwards through the calculation. It asks, in effect: “Which weights contributed to this error, in which direction, and by approximately how much?” It computes gradients. A gradient is an instruction about how changing a weight would change the loss. An optimiser such as Adam uses those gradients to adjust the weights by tiny amounts.
A kitchen analogy helps. You bake a cake and discover it is too salty. The taste is the loss signal. Backpropagation estimates how much each ingredient contributed. The optimiser changes the recipe slightly, perhaps reducing salt and adjusting sugar. You bake again. No single cake teaches the whole craft, but millions of small corrections produce a competent recipe.
Training is organised into batches because hardware processes many examples together. One optimiser step reflects the average signal from a batch rather than one sentence. An epoch means one pass through a defined dataset, although frontier models often train on enormous streams where the more useful measure is the number of tokens processed.
Pre-training and backpropagation are not alternatives. Pre-training is the stage in which the model receives its broad education. Backpropagation is the standard mechanism used to update weights during that stage. DeepSeek-V3, for example, describes pre-training on 14.8 trillion tokens, followed by supervised fine-tuning and reinforcement-learning stages. [3]
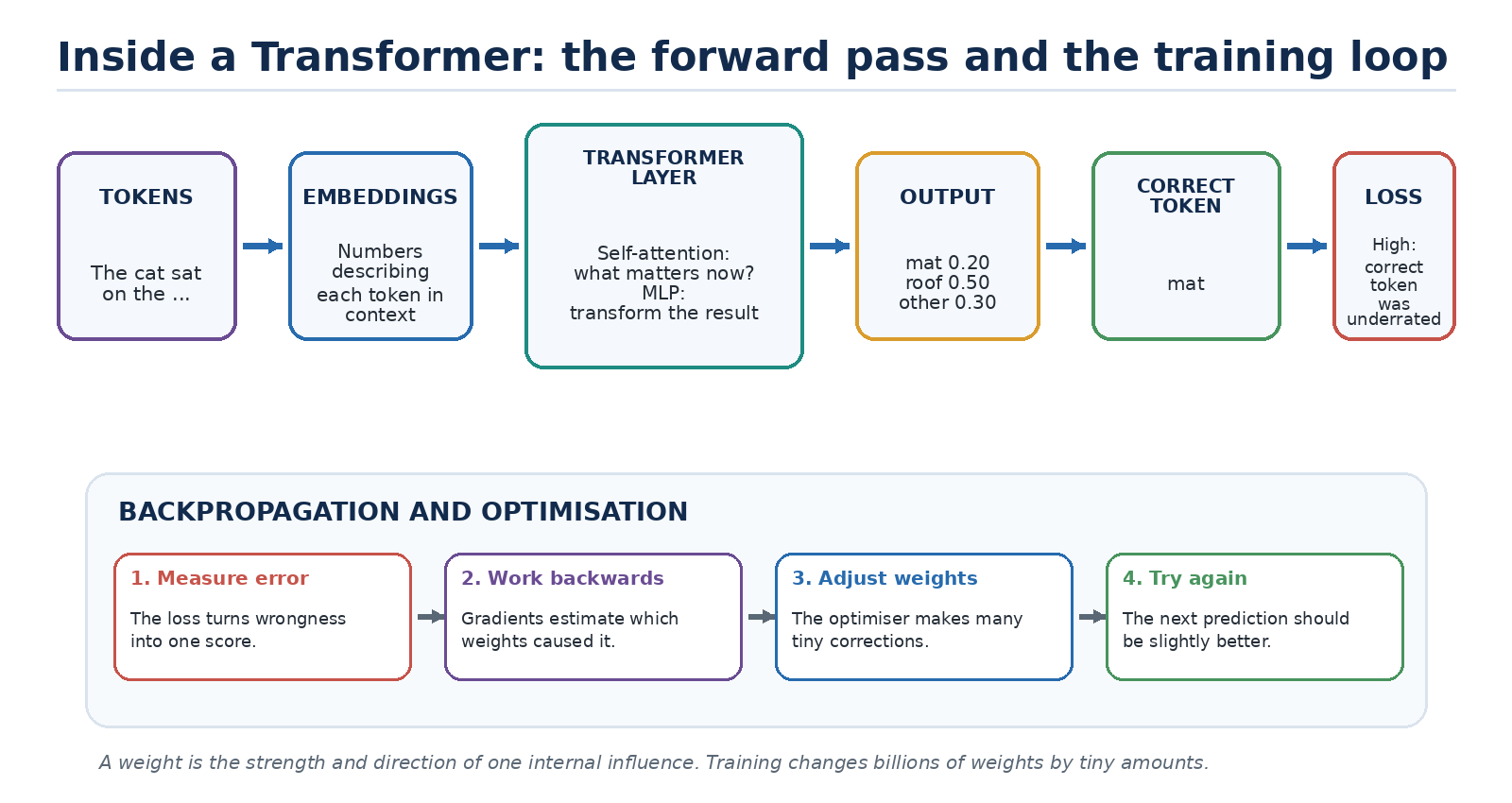
Figure 2. A simplified Transformer forward pass and the training loop that updates model weights.
5. FP16 and mixed-precision storage
Weights and calculations must be stored as numbers. FP32 uses 32-bit floating-point numbers. FP16 uses 16 bits, so each stored value occupies two bytes. BF16 also uses 16 bits but allocates its bits differently, preserving a wider numerical range at the cost of some fine precision.
An eight-billion-parameter model stored entirely in FP16 needs roughly sixteen gigabytes for the weights alone: eight billion values multiplied by two bytes. Runtime software, temporary activations and the key-value cache require additional memory.
Mixed-precision training uses different numerical formats for different jobs. Many weights and calculations can use FP16 or BF16 to save memory and increase speed, while sensitive accumulations or master copies remain in FP32. The original mixed-precision work also used loss scaling to prevent very small gradients from becoming zero when represented in FP16. [4]
Think of measuring a room. Millimetres are useful for fitting cabinetry, but you do not need millimetres to describe the distance between cities. Mixed precision uses detailed measurements where they matter and cheaper measurements where they are sufficient.
6. Fine-tuning and specialisation
A base model is mainly trained to continue text. It may know a great deal but still be awkward as an assistant. Supervised fine-tuning teaches it to respond to instructions by training on prompt-and-answer examples. Preference training then compares alternative responses and rewards behaviour judged more helpful, accurate or safe. InstructGPT demonstrated that a much smaller instruction-tuned model could be preferred by human evaluators over a far larger base model that had not been tuned to follow intent. [6]
Fine-tuning every weight is expensive. LoRA, or Low-Rank Adaptation, freezes the original weights and trains a much smaller set of additional matrices that steer the model towards a domain or style. It is like attaching a specialised navigation module rather than rebuilding the entire vehicle. LoRA can greatly reduce the number of trainable parameters and the memory required for adaptation. [5]
This is also where specialisations emerge. Starting from one base model, developers may create a chat model, a coding model, a medical model, a tool-use model or a reasoning model. Some specialisation lives in changed weights; some is supplied at runtime through system prompts, retrieved documents and tools.
7. Knowledge distillation using DeepSeek-style teachers
Knowledge distillation trains a smaller student using outputs produced by a stronger teacher. The student does not receive a copy of the teacher’s weights. Instead, it studies a large set of examples created or scored by the teacher.
For example, a teacher such as DeepSeek-R1 might receive: “A shop discounts a $120 item by 25 per cent and then adds 10 per cent tax. What is the final price?” The teacher produces a worked solution. A verification program checks the arithmetic. If the answer is correct and the explanation is clear, the prompt and response enter the student’s training set. The student is then fine-tuned on thousands or millions of such examples.
This is synthetic data because the answer was generated by a model rather than written directly by a person. Synthetic does not mean fake or useless. It means machine-produced. High-quality synthetic data can cheaply cover many difficulty levels and variations. DeepSeek used DeepSeek-R1 to distil reasoning behaviour into smaller Qwen and Llama models. [8]
How does the student actually learn? It still uses a loss function and backpropagation. When its response differs from the approved teacher response, gradients adjust its weights so that similar prompts are more likely to produce the desired pattern. Distillation is therefore a way of constructing the curriculum and targets; backpropagation remains the learning mechanism.
Teacher errors are a serious problem. A confident teacher can produce false facts, invalid code, a biased judgement or a plausible-looking reasoning chain with a hidden mistake. Distillation can preserve those errors and repeat them at scale. It may also narrow the student’s style if every example sounds alike.
Mitigation happens before and after training. Developers can reject low-confidence outputs, use calculators or code execution for verifiable tasks, ask a second model to critique answers, compare several independent solutions, include human review for sensitive domains, and hold back test questions that were never used in training. For mathematics, the final numeric answer can be checked automatically. For code, unit tests can run. For factual material, retrieval from cited sources can provide an independent check. The goal is not merely more synthetic data; it is a smaller amount of trusted synthetic data with measurable quality.
8. Ordinary quantisation: GPTQ, AWQ and safeguards
Post-training quantisation compresses an already-trained model by storing its weights with fewer bits. An FP16 weight such as 0.72 might be represented by the nearest available low-bit value, perhaps 0.7. At four bits, there are far fewer possible values than in FP16, but often enough to preserve most useful behaviour.
The simplest analogy is reducing a photograph from millions of colours to a smaller palette. If the palette is still rich, the picture remains recognisable. If it has only two colours, subtle shading disappears.
GPTQ stands for GPT Quantisation. It is a one-shot post-training method that uses information about how errors propagate through a layer to choose rounded values that do the least overall damage. Rather than rounding every weight independently, it compensates for one rounding decision with adjustments to others. The original work showed useful 3-bit and 4-bit compression with small accuracy losses on large models. [9]
AWQ stands for Activation-aware Weight Quantisation. An activation is the temporary signal produced inside the model when it processes real input. AWQ uses representative prompts to discover which weight channels have unusually important effects on those activations. It then rescales those channels so that low-bit rounding damages them less. The authors report that protecting a small fraction of salient weights can substantially reduce error. [10]
Quantisation damage is not evenly distributed. Small but meaningful differences may vanish. Large outlier weights may dominate a scale and leave too little precision for ordinary values. Some attention or output layers can be more sensitive than others. A model may remain fluent while losing arithmetic accuracy, instruction following or specialised knowledge.
Several safeguards help:
- Calibration data: run realistic sample prompts through the model so the quantiser sees the distributions it must preserve.
- Group-wise scales: give small groups of weights separate scaling factors instead of forcing an entire layer to share one scale.
- Mixed-bit protection: keep sensitive layers or outlier channels at higher precision.
- Quantisation-aware training: fine-tune while simulating the low-bit restriction so the network adapts before final packing.
- Task testing: benchmark the exact abilities required, not just average language-model loss.
For example, a local coding assistant should be tested on compilation and unit tests after quantisation. If a 3-bit version produces fast but subtly broken code while a 4-bit version remains reliable, the 4-bit file is the better compression. The smallest model is not automatically the most useful one.
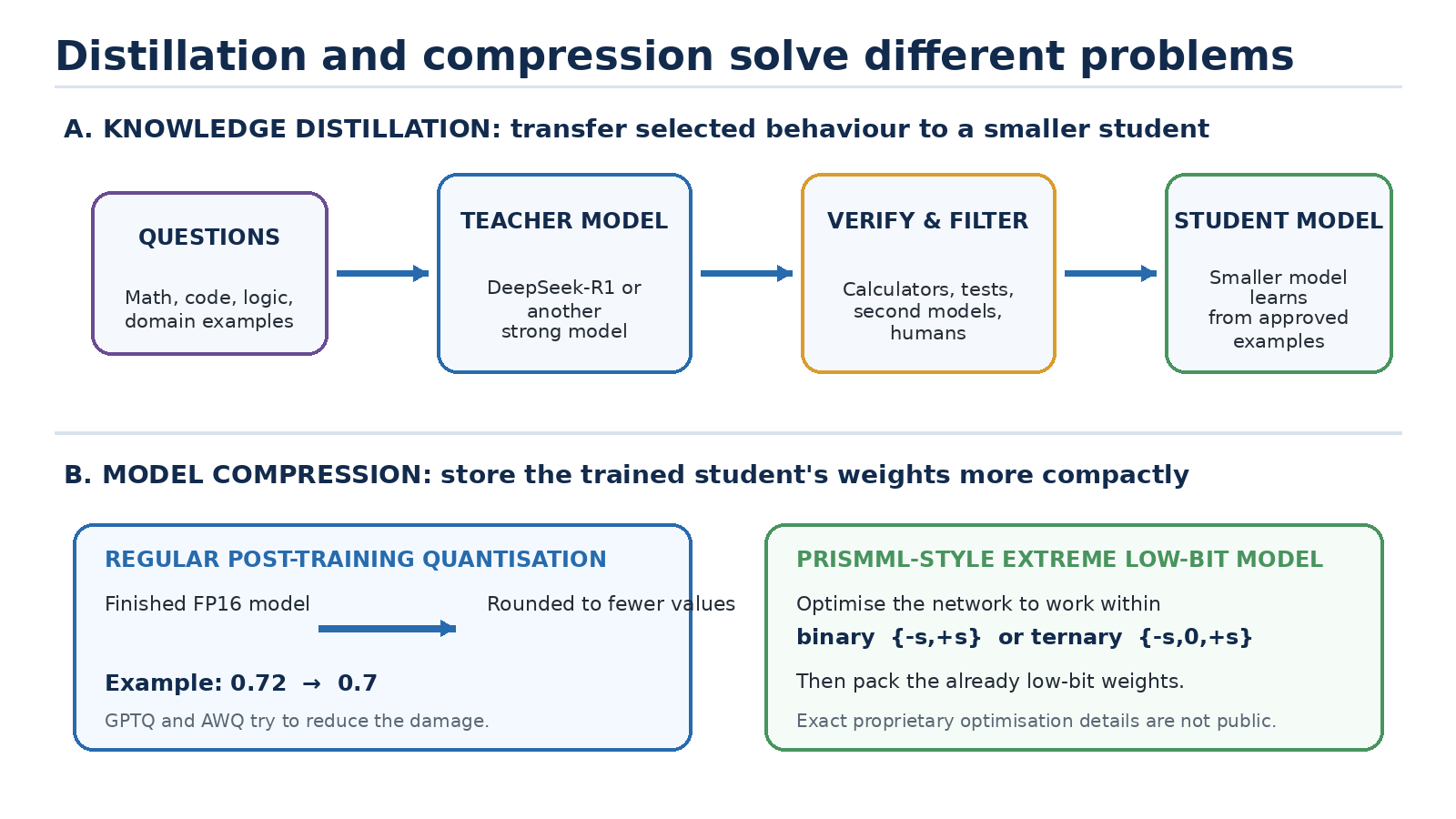
Figure 3. Distillation transfers behaviour; quantisation compresses the resulting model.
9. PrismML’s binary and ternary approach
PrismML’s Bonsai models push low-bit representation much further. A binary model restricts each weight to two signed states. A ternary model allows three: negative, zero and positive. PrismML describes its ternary weights as {-s, 0, +s}, with a shared FP16 scale s for each group of 128 weights. [11]
The zero state matters. In a binary model, a connection must contribute in one direction or the other. In a ternary model, the optimiser can also switch an unhelpful connection off. Three states contain about 1.58 bits of information, although practical file formats may use two physical bits per weight for efficient packing.
This differs from naive one-bit post-training rounding. If an ordinary finished model contains weights 0.72, 0.12 and -0.03, simply forcing them into two states can erase important differences. PrismML says Bonsai is optimised to function while embeddings, attention projections, MLPs and the language-model head all obey the severe binary or ternary constraint. The already low-bit weights are then packed efficiently for deployment. [11–13]
The hard part is not writing -1, 0 and +1 into a compact file. The hard part is finding a network that still performs useful language and reasoning tasks when billions of weights have so few choices. PrismML’s exact optimisation recipe is proprietary, so public sources do not establish precisely how much occurs during original pre-training, retraining or specialised conversion. It should not be claimed that the method avoids backpropagation unless the company publishes evidence of that. PrismML’s performance and energy figures should also be treated as vendor-reported until independently reproduced. [11, 12]
10. Safety alignment and guardrails
People often speak of “the safety layer”, but alignment is usually not one literal neural-network layer that can be pointed to and removed. It is a stack of training methods and runtime controls.
First, supervised instruction tuning provides examples of helpful and unacceptable behaviour. Second, preference training uses human or AI judgements to rank responses. Reinforcement Learning from Human Feedback, or RLHF, uses those rankings to optimise the assistant’s behaviour. [6] Constitutional AI uses written principles, model-generated critiques and AI feedback to help train safer responses with fewer direct human labels. [7]
Third, system prompts set rules for a particular deployment. Fourth, input and output classifiers can detect categories such as self-harm, malware, personal data or abuse. Fifth, tool permissions limit what an agent can actually do. A model may be allowed to draft an email but not send it; read a database but not delete records; propose code but require tests and human approval before deployment.
These controls can fail in different ways. Overly weak alignment may allow harmful or reckless behaviour. Overly blunt alignment may refuse harmless requests or distort a user’s meaning. Good safety engineering therefore combines model training, clear policies, least-privilege tools, logging, testing and human review for high-impact actions.
A useful analogy is aviation safety. Safety is not one bolt in the aircraft. It includes design standards, pilot training, checklists, air-traffic control, maintenance, alarms and incident investigation. Removing one guardrail does not create freedom; it may merely move risk to a less visible place.
11. Chat, reasoning, tool-calling and agent models
A chat model is optimised for natural conversation and direct answers. A reasoning model is trained or prompted to spend more computation on difficult multi-step problems. It may generate an internal or visible reasoning process, test alternatives, revise a plan or use reinforcement learning on verifiable tasks. DeepSeek-R1 showed that reinforcement learning could produce strong reasoning behaviours, while its polished R1 model added cold-start and supervised stages to improve readability and reliability. [8]
A reasoning model is not necessarily larger than a chat model, but it often uses more tokens and time per answer. For “What is the capital of Japan?”, extended reasoning is wasteful. For debugging a distributed system or proving a mathematical result, deliberate search may help.
Tool calling adds another capability. The model is given structured descriptions of tools, such as a calculator, web search, calendar, database or code interpreter. Instead of inventing the result, it emits a structured request: tool name plus arguments. The surrounding application executes the tool and returns the result to the model. Toolformer studied models learning when and how to call APIs, while ReAct combined reasoning with actions and observations from external environments. [14, 15]
An agent is more than a single tool call. It operates in a loop: 1. Interpret the goal. 2. Make a plan. 3. Choose an action or tool. 4. Observe the result. 5. Update the plan. 6. Continue until a stopping condition is met.
The model supplies judgement and language; the agent harness supplies persistence, tools, permissions, memory and control flow. A plain model answers, “Here is how you could book the trip.” An agent may search flights, compare constraints, draft an itinerary and ask for approval before purchasing.
A quick comparison
| Type | Primary behaviour | Typical strength | Main limitation |
|---|---|---|---|
| Chat model | Responds conversationally | Fast natural interaction | May answer too quickly on hard problems |
| Reasoning model | Uses extra inference effort | Multi-step logic, maths, planning | Slower and uses more tokens |
| Tool-calling model | Requests structured external actions | Fresh facts, exact calculation, APIs | Depends on tool schemas and permissions |
| Agentic system | Plans, acts, observes and repeats | Longer tasks across tools and memory | Error accumulation and control complexity |
12. Context windows, caching, KV cache and speculative decoding
The context window is the amount of material the model can consider in one request: system instructions, conversation history, documents, tool definitions, tool results and the new output. It is working memory, not the model’s entire learned knowledge. A larger context window can hold longer documents, but more context is not automatically better. Important details can become harder to retrieve as irrelevant material accumulates. [16]
The key-value cache, or KV cache, is different. During generation, each Transformer layer calculates key and value representations for earlier tokens. Without a KV cache, the model would repeatedly recalculate those representations every time it generated another token. The cache stores them, speeding generation, but grows with the conversation length and can consume substantial RAM or VRAM. PagedAttention and vLLM manage KV-cache memory in blocks to reduce fragmentation and improve throughput. [17]
Prompt caching is different again. A provider or local serving system may save the processed representation of an identical prompt prefix, such as a long system prompt, tool catalogue or reference manual. A later request with the same prefix can reuse that work. This reduces latency and compute cost, but the cached tokens still belong to the model’s context. [18]
“Turbo Cache” is not one standard technical term across the field. Vendors may use similar language for prompt caching, prefix caching, a faster KV-cache implementation or a combination of optimisations. The precise questions to ask are: What is cached? Where is it stored? How long does it live? Does it save computation, memory, cost or all three?
Speculative decoding accelerates token generation using a small draft model. The small model quickly proposes several tokens; the larger target model checks them in parallel. Accepted tokens are kept, and rejected ones are corrected. When the draft predicts well, several tokens are produced for roughly the cost of verifying them, without changing the target model’s output distribution. [19]
Active parameters matter in mixture-of-experts models. A dense 70-billion-parameter model generally uses all its weights for each token. A sparse mixture-of-experts model contains several expert MLP blocks, but a router selects only a few for each token. Mixtral 8x7B has roughly 47 billion accessible parameters but uses about 13 billion active parameters per token. [20] DeepSeek-V3 reports 671 billion total parameters with 37 billion activated per token. [3] This can increase capacity without paying the full computation cost on every token, although the complete model weights may still need to be stored or distributed across devices.
For local hardware, three memory pools matter:
- Model weights: mostly fixed while the model is loaded.
- KV cache and temporary activations: grow with context and concurrent users.
- Application memory: the operating system, agent framework, tools, retrieved documents and other software.
A model that barely fits may run poorly because no space remains for the KV cache. Leaving memory headroom is often more valuable than squeezing in a nominally larger model.
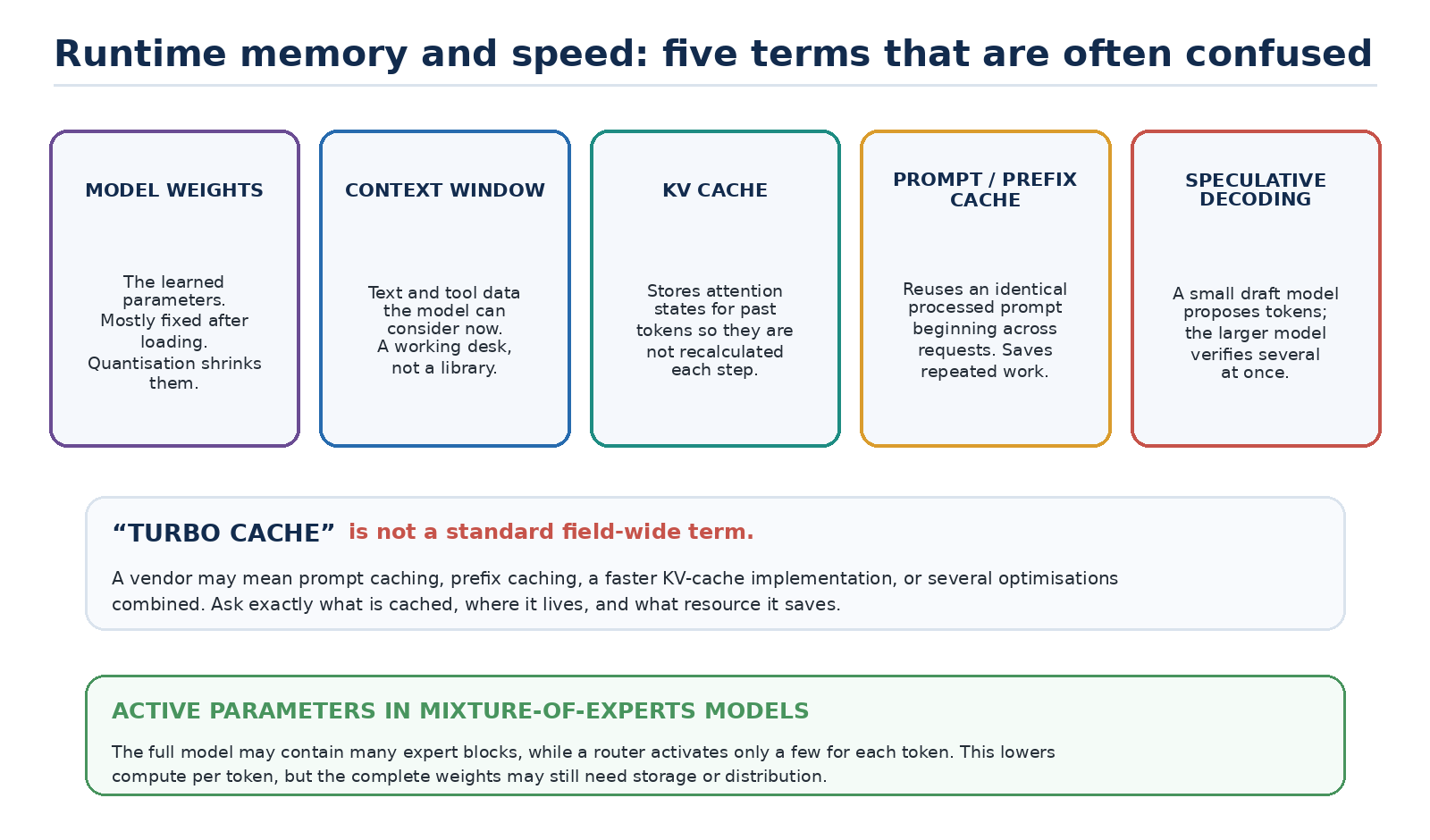
Figure 4. Model weights, context windows, KV cache, prompt caching and speculative decoding are related but distinct.
13. Agentic memory, learning and skills
An agent can appear to learn in several different ways, and they should not be confused.
In-context learning means the model adapts temporarily from examples inside the current prompt. Its weights do not change. Long-term memory stores information outside the model, such as summaries, user preferences, completed tasks or documents. Retrieval-Augmented Generation, or RAG, searches an external knowledge store and places relevant passages into the context before the model answers. This makes knowledge easier to update and cite without retraining the weights. [21]
Agent memory systems often divide memory into tiers: recent conversation, compressed summaries, searchable records and durable facts. MemGPT compared this to an operating system moving information between fast and slow memory so an agent can work beyond the fixed context window. [22] Generative-agent research similarly used records, retrieval, reflection and planning to create persistent behaviour. [23]
A skill is a reusable package of instructions and resources for a task. It may include a Markdown guide, scripts, templates, examples and tests. Skills are loaded when relevant rather than permanently crowding every prompt. Anthropic’s Agent Skills documentation describes this as modular, filesystem-based expertise that can be composed into specialist capabilities. [24]
True weight learning is different. Fine-tuning or LoRA updates model parameters and should happen through a controlled training process with evaluation and rollback. Allowing an autonomous agent to rewrite its own weights after every interaction would risk catastrophic drift, data poisoning and loss of earlier abilities. Most practical “learning agents” therefore update memory, retrieval indexes, skills and workflow rules much more often than they update the underlying model.
14. Multi-agent orchestration and profile files
Multi-agent orchestration gives different model instances specialised roles and coordinates their work. The agents may use the same underlying model with different prompts, or different models chosen for cost and capability.
A profile file is simply a maintainable way of storing prompt context. Names such as system.md, user.md or soul.md are conventions, not universal standards. A sensible set might be:
- system.md: role, rules, safety requirements and authority.
- soul.md: values, voice and behavioural philosophy.
- user.md: stable user preferences and relevant background.
- tools.md: available tools, schemas and permission boundaries.
- memory.md: current durable facts and unfinished work.
- task.md: the immediate objective and acceptance criteria.
At runtime, the orchestrator assembles selected files into the system and user prompt contexts. System instructions usually have higher authority and define how the agent should behave. User content supplies the current request and user-controlled material. Retrieved documents and tool results should be clearly delimited so that text inside them is treated as data rather than trusted instructions.
Consider a software task. A planner agent turns the request into requirements. An architect agent proposes components and interfaces. A builder agent writes code. A reviewer agent checks security and maintainability. A test agent runs automated tests. The orchestrator passes structured artefacts between them and decides when to retry, escalate or stop. AutoGen supports configurable multi-agent conversations, while ChatDev explored specialised agents cooperating across design, coding and testing. [25, 26]
An “agent swarm” does not become wise merely by adding more agents. Multiple models can repeat the same mistake, amplify false consensus and consume enormous context. Effective orchestration needs role separation, independent checks and clear decision rights. For example, the reviewer should not simply see the builder’s confident conclusion; it should receive the requirements, code and test results and be asked to find failures. A final judge can compare competing proposals against explicit criteria.
Hybrid local-and-cloud workflows are especially useful. A small local model can classify requests, manage private notes, retrieve documents and perform routine drafting. A stronger cloud reasoning model can be called only for difficult planning or review. Sensitive data can be redacted or summarised before leaving the device. Alternatively, a powerful local model on unified memory can perform the entire workflow offline.
The orchestration layer can route work according to policy:
- Cheap local model for short classification and formatting.
- Specialist coding model for implementation.
- Reasoning model for architecture or complex diagnosis.
- Vision model for images and scanned documents.
- Human approval for financial, legal, medical or irreversible actions.
The important insight is that the agent’s identity and competence are not stored in one place. They emerge from the base model, profile prompts, tools, memory, skills, workflow and permissions. Changing soul.md may alter tone; adding a calculator improves arithmetic; adding retrieval updates factual access; swapping the model changes underlying capability. These components should be versioned and tested separately.
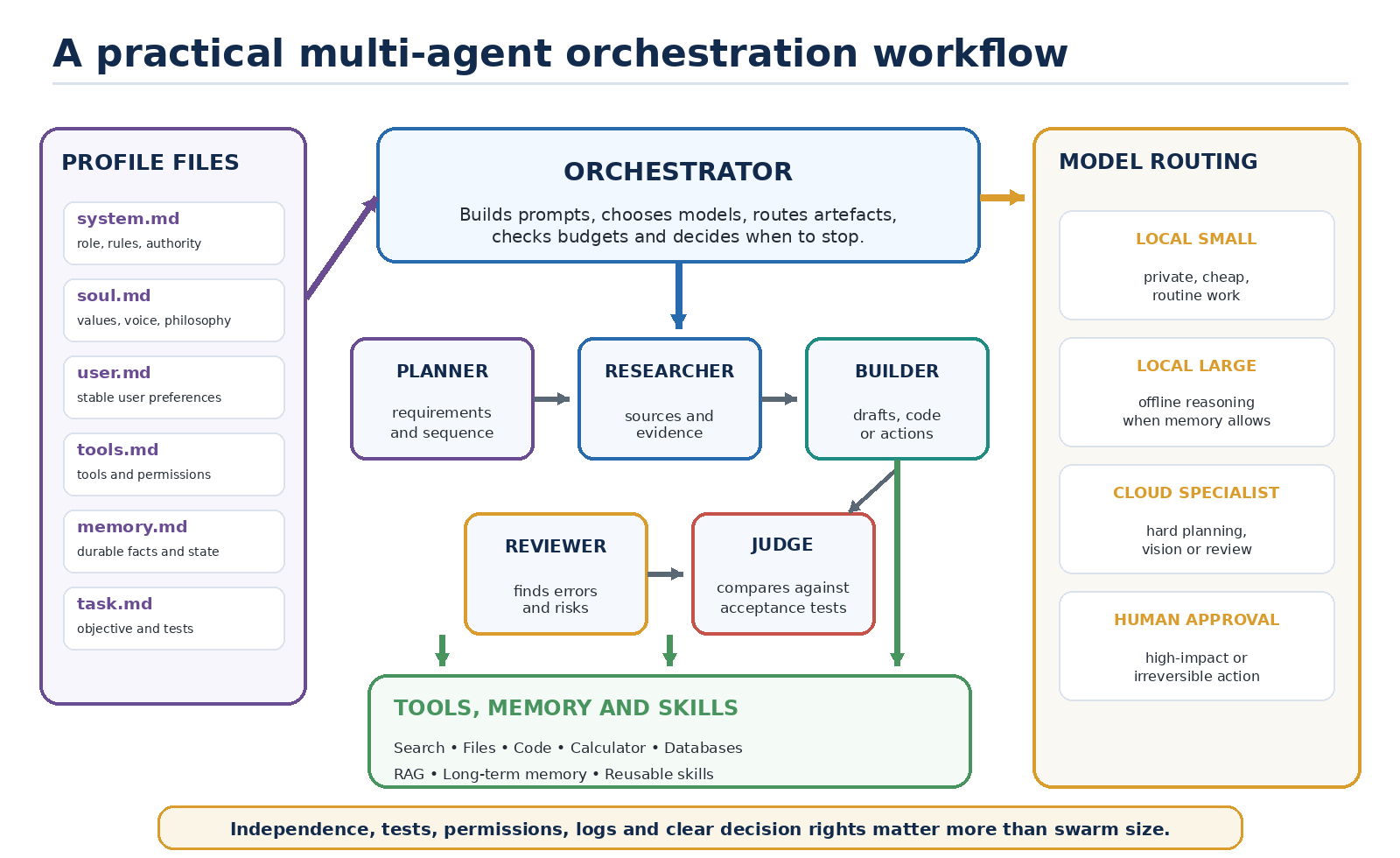
Figure 5. A multi-agent workflow combining profile files, specialised agents, tools, memory and model routing.
15. A practical local-AI pipeline
A sensible route to a high-performance local system is:
- Define the jobs. Decide whether the system needs conversation, coding, long-document analysis, reasoning, tools or autonomous workflows.
- Choose the base model family and size. Check licences, context support, tool use and hardware kernels.
- Select or curate a syllabus for any domain adaptation. Keep training, validation and final test sets separate.
- Fine-tune with supervised examples or LoRA where prompting and retrieval are insufficient.
- Use a strong teacher such as DeepSeek-R1 to create candidate reasoning examples, but verify and filter them.
- Add alignment examples, tool permissions and runtime guards suited to the actual risks.
- Evaluate the FP16 or BF16 reference model before compression.
- Quantise several candidates, perhaps 8-bit, 6-bit and 4-bit, and compare them on real tasks.
- Leave enough memory for context and KV cache rather than filling every byte with weights.
- Add RAG, memory and skills before assuming the model needs more parameter training.
- Introduce agent orchestration gradually, with logs, tests, budgets and human approval points.
- Measure quality, tokens per second, first-token latency, peak memory, energy use and failure rates.
The future of useful local AI is unlikely to be one enormous model doing everything. It is more likely to combine compact specialised models, efficient low-bit storage, retrieval, tools, persistent memory and selective access to stronger models. The winning system will not merely have the smallest file or the largest context window. It will place the right capability in the right layer and preserve enough transparency to understand why it works.
16. Key takeaways
A language model begins with a curated syllabus and learns next-token prediction through loss, backpropagation and optimisation. Transformer layers combine attention, which gathers relevant context, with MLPs, which transform that information. FP16 and mixed precision reduce training and storage costs; instruction tuning and alignment shape behaviour; distillation transfers selected abilities from a teacher to a smaller student.
Ordinary quantisation rounds a completed model into fewer numerical levels. GPTQ compensates for rounding error, while AWQ protects activation-important channels. PrismML claims a deeper binary or ternary optimisation in which the model functions under an extreme low-bit constraint before the weights are packed.
At runtime, context windows, KV caches, prompt caches, speculative decoding and active parameters determine speed and memory use. Tools turn a model into an actor; memory and retrieval give it continuity; skills provide reusable procedures; and orchestration coordinates specialised agents. Understanding these layers makes it much easier to design a local AI system that is compact, capable and honest about its limitations.
References
Source note: PrismML performance, size and energy figures are vendor-reported unless independently reproduced. This manual relies on PrismML’s public descriptions for its weight formats and conceptual claims, while clearly marking the proprietary optimisation recipe as undisclosed.
| Ref | Year | Author(s) | Title | Source |
|---|---|---|---|---|
| [1] | 2024 | A. Dubey et al. | The Llama 3 Herd of Models | arXiv:2407.21783 |
| [2] | 2017 | A. Vaswani et al. | Attention Is All You Need | arXiv:1706.03762 |
| [3] | 2024 | DeepSeek-AI et al. | DeepSeek-V3 Technical Report | arXiv:2412.19437 |
| [4] | 2017 | P. Micikevicius et al. | Mixed Precision Training | arXiv:1710.03740 |
| [5] | 2021 | E. Hu et al. | LoRA: Low-Rank Adaptation of Large Language Models | arXiv:2106.09685 |
| [6] | 2022 | L. Ouyang et al. | Training Language Models to Follow Instructions with Human Feedback | arXiv:2203.02155 |
| [7] | 2022 | Y. Bai et al. | Constitutional AI: Harmlessness from AI Feedback | arXiv:2212.08073 |
| [8] | 2025 | DeepSeek-AI et al. | DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning | arXiv:2501.12948 |
| [9] | 2022 | E. Frantar et al. | GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers | arXiv:2210.17323 |
| [10] | 2023 | J. Lin et al. | AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration | arXiv:2306.00978 |
| [11] | 2026 | PrismML | Introducing Ternary Bonsai: Top Intelligence at 1.58 Bits | prismml.com |
| [12] | 2026 | PrismML | Announcing 1-bit Bonsai: The First Commercially Viable 1-bit LLMs | prismml.com |
| [13] | 2026 | PrismML | Ternary-Bonsai-8B-mlx-2bit model card | huggingface.co |
| [14] | 2023 | T. Schick et al. | Toolformer: Language Models Can Teach Themselves to Use Tools | arXiv:2302.04761 |
| [15] | 2022 | S. Yao et al. | ReAct: Synergizing Reasoning and Acting in Language Models | arXiv:2210.03629 |
| [16] | 2026 | Anthropic | Context Windows (Claude Platform Documentation) | platform.claude.com |
| [17] | 2023 | W. Kwon et al. | Efficient Memory Management for LLM Serving with PagedAttention | arXiv:2309.06180 |
| [18] | 2026 | Anthropic | Prompt Caching (Claude Platform Documentation) | platform.claude.com |
| [19] | 2022 | Y. Leviathan, M. Kalman, Y. Matias | Fast Inference from Transformers via Speculative Decoding | arXiv:2211.17192 |
| [20] | 2024 | A. Jiang et al. | Mixtral of Experts | arXiv:2401.04088 |
| [21] | 2020 | P. Lewis et al. | Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks | arXiv:2005.11401 |
| [22] | 2023 | C. Packer et al. | MemGPT: Towards LLMs as Operating Systems | arXiv:2310.08560 |
| [23] | 2023 | J. Park et al. | Generative Agents: Interactive Simulacra of Human Behavior | arXiv:2304.03442 |
| [24] | 2026 | Anthropic | Agent Skills Overview (Claude Platform Documentation) | platform.claude.com |
| [25] | 2023 | Q. Wu et al. | AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation | arXiv:2308.08155 |
| [26] | 2023 | C. Qian et al. | ChatDev: Communicative Agents for Software Development | arXiv:2307.07924 |
Terminology note: product names and vendor features change rapidly. The conceptual distinctions in this manual are more durable than any particular model version or marketing label.